NumPy¶
- 행렬 연산을 위한 핵심 라이브러리
- “Numerical Python“의 약자
- 대규모 다차원 배열과 행렬 연산에 필요한 다양한 함수를 제공
- 파이썬 list 객체를 개선한 NumPy의 ndarray 객체를 사용
- 과학계산 패키지 대부분이 NumPy 배열 객체로 데이터 교환 출처 : http://taewan.kim/post/numpy_cheat_sheet/
NumPy 배열¶
- 고성능 다차원 배열과 이런 배열을 처리하는 다양한 함수와 툴을 제공
In [1]:
%%html
<!-- 에디터 폰트를 조정합니다. -->
<style type='text/css'>
.CodeMirror{
font-size: 14px;
font-family: consolas;
</style>
In [2]:
# import
import numpy as np
In [4]:
# 버젼 확인
np.__version__
Out[4]:
- <그림 1>과 같이 다차원 배열을 지원
- NumPy 배열의 구조는 “Shape“으로 표현
- Shape은 배열의 구조를 파이썬 튜플 자료형을 이용하여 정의
- http://taewan.kim/post/numpy_sum_axis/
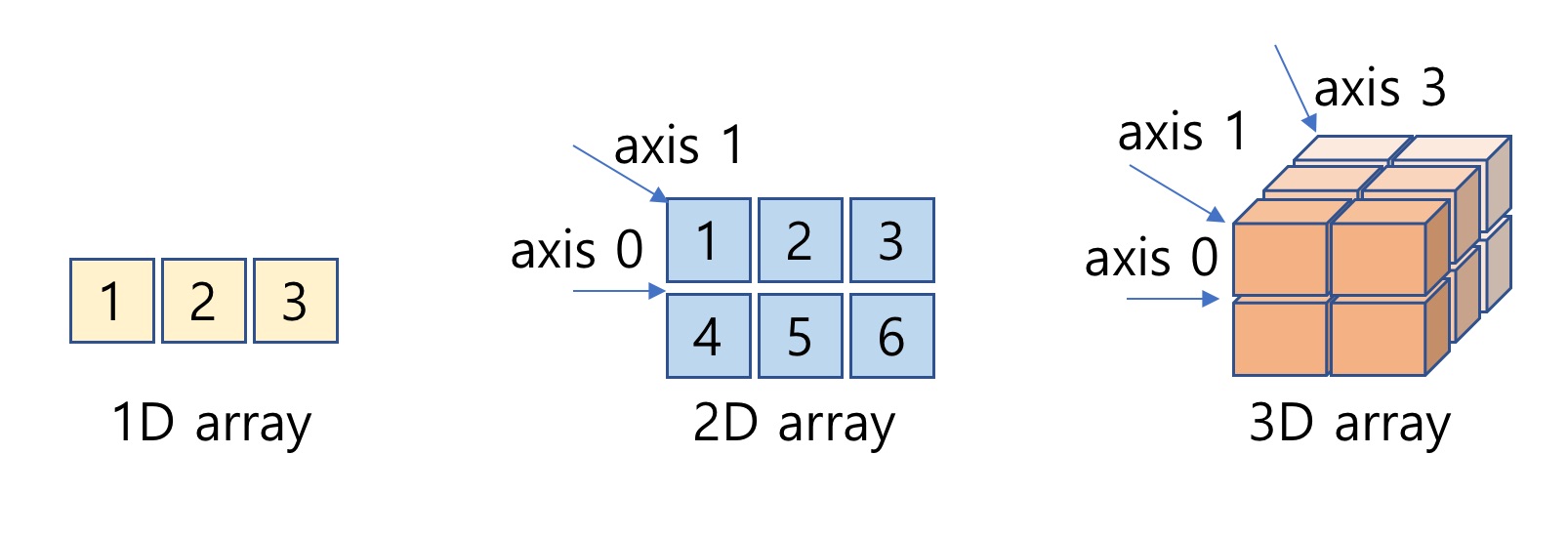 그림 1: NumPy 1차원, 2차원 및 3차원 배열과 Axis
그림 1: NumPy 1차원, 2차원 및 3차원 배열과 Axis
In [1]:
#NumPy 객체의 정보를 출력
def pprint(arr):
print("type:{}".format(type(arr)))
print("shape: {}, dimension: {}, dtype:{}".format(arr.shape, arr.ndim, arr.dtype))
print("Array's Data:\n", arr)
배열 생성¶
- NumPy 배열은 numpy.ndarray 객체
파이썬 배열로 NumPy 배열 생성¶
- 파이썬 배열을 인자로 NumPy 배열을 생성
- 파라미터로 list 객체와 데이터 타입(dtype)을 입력하여 NumPy 배열을 생성
- dtype을 생략할 경우, 입력된 list 객체의 요소 타입이 설정
파이썬 1차원 배열(list)로 NumPy 배열 생성¶
In [31]:
# 파이썬 1차원 배열(list)로 NumPy 배열 생성
arr = [1, 2, 3]
a = np.array(arr)
pprint(a)
파이썬 2차원 배열로 NumPy 배열 생성, 원소 데이터 타입 지정¶
In [33]:
# 파이썬 2차원 배열로 NumPy 배열 생성, 원소 데이터 타입 지정
arr = [(1,2,3), (4,5,6)]
a= np.array(arr, dtype = float)
pprint(a)
파이썬 3차원 배열로 NumPy 배열 생성, 원소 데이터 타입 지정¶
In [34]:
arr = np.array(
[
[[1,2,3], [4,5,6]],
[[3,2,1], [4,5,6]]
]
, dtype = float)
a= np.array(arr, dtype = float)
pprint(a)
배열 생성 및 초기화¶
- 원하는 shape으로 배열을 설정
- 각 요소를 특정 값으로 초기화
- zeros, ones, full, eye 함수
- 파라미터로 입력한 배열과 같은 shape의 배열을 만드는 zeros_like, ones_like, full_like 함수
np.zeros 함수¶
- zeros(shape, dtype=float, order='C')
- 지정된 shape의 배열을 생성하고, 모든 요소를 0으로 초기화
In [36]:
a = np.zeros((3,4))
pprint(a)
np.ones 함수¶
- np.ones(shape, dtype=None, order='C')
- 지정된 shape의 배열을 생성하고, 모든 요소를 1로 초기화
In [38]:
a = np.ones((2,3,4),dtype=np.int16)
pprint(a)
np.full 함수¶
- np.full(shape, fill_value, dtype=None, order='C')
- 지정된 shape의 배열을 생성하고, 모든 요소를 지정한 "fill_value"로 초기화
In [39]:
a = np.full((2,2),7)
pprint(a)
np.eye 함수¶
- np.eye(N, M=None, k=0, dtype=<class 'float'>)
- (N, N) shape의 단위 행렬(Unit Matrix)을 생성
In [40]:
np.eye(4)
Out[40]:
np.empty 함수¶
- empty(shape, dtype=float, order='C')
- 지정된 shape의 배열 생성
- 요소의 초기화 과정에 없고, 기존 메모리값을 그대로 사용
- 배열 생성비용이 가장 저렴하고 빠름
- 배열 사용 시 주의가 필요(초기화를 고려)
In [42]:
a = np.empty((4,2))
pprint(a)
like 함수¶
- numpy는 지정된 배열과 shape이 같은 행렬을 만드는 like 함수를 제공합니다.
- np.zeros_like
- np.ones_like
- np.full_like
- np.empty_like
In [44]:
a = np.array([[1,2,3], [4,5,6]])
b = np.ones_like(a)
pprint(b)
In [45]:
a = np.array([[1,2,3], [4,5,6]])
b = np.zeros_like(a)
pprint(b)
In [49]:
a = np.array([[1,2,3], [4,5,6]])
b = np.full_like(a, 7)
pprint(b)
In [48]:
a = np.array([[1,2,3], [4,5,6]])
b = np.empty_like(a)
pprint(b)
데이터 생성 함수¶
- 주어진 조건으로 데이터를 생성한 후, 배열을 만드는 데이터 생성 함수
- numpy.linspace
- numpy.arange
- numpy.logspace
np.linspace 함수¶
- numpy.linspace(start, stop, num=50, endpoint=True, dtype=None)
- start부터 stop의 범위에서 num개를 균일한 간격으로 데이터를 생성하고 배열을 만드는 함수
- 요소 개수를 기준으로 균등 간격의 배열을 생성
In [69]:
a = np.linspace(0, 1, 5)
pprint(a)
In [64]:
# endpoint : stop 값 포함 여부
a = np.linspace(0, 1, 5, endpoint=False)
pprint(a)
In [71]:
# dtype : 값 타입 설정
a = np.linspace(0, 1, 5, dtype=np.int)
pprint(a)
In [70]:
# linspace의 데이터 추출 시각화
import matplotlib.pyplot as plt
plt.plot(a, 'o')
plt.show()

np.arange 함수¶
- numpy.arange([start,] stop[, step,], dtype=None)
- start부터 stop 미만까지 step 간격으로 데이터 생성한 후 배열을 만듦
- 범위내에서 간격을 기준 균등 간격의 배열
- 요소의 갯수가 아닌 데이터의 간격을 기준으로 배열 생성
In [75]:
a = np.arange(0, 10, 2, np.float)
pprint(a)
In [73]:
# arange의 데이터 추출 시각화
import matplotlib.pyplot as plt
plt.plot(a, 'o')
plt.show()

np.geomspace 함수¶
- np.geomspace(start, stop, num=50, endpoint=True, dtype=None)
- 로그 스케일의 linspace 함수
- 로그 스케일로 지정된 범위에서 num 개수만큼 균등 간격으로 데이터 생성한 후 배열 만듦
In [80]:
a = np.geomspace(0.1, 1, 20, endpoint=True)
pprint(a)
In [81]:
# logspace의 데이터 추출 시각화
import matplotlib.pyplot as plt
plt.plot(a, 'o')
plt.show()

2.4 난수 기반 배열 생성¶
난수 발생 및 배열 생성을 생성하는 numpy.random 모듈
np.random.normal
- np.random.rand
- np.random.randn
- np.random.randint
- np.random.random
np.random.normal¶
- normal(loc=0.0, scale=1.0, size=None)
- 정규 분포 확률 밀도에서 표본 추출
- loc: 정규 분포의 평균
- scale: 표준편차
- 평균과 표준편차가 0, 1이면 np.random.randn 와 동일
In [89]:
mean = 0
std = 1
a = np.random.normal(mean, std, (2, 3))
pprint(a)
- np.random.normal이 생성한 난수는 정규 분포의 형상
- 다음 예제는 정규 분포로 10000개 표본을 뽑은 결과를 히스토그램으로 표현한 예
- 표본 10000개의 배열을 100개 구간으로 구분할 때, 정규 분포 형태
In [98]:
data = np.random.normal(0, 1, 10000)
import matplotlib.pyplot as plt
plt.hist(data, bins=30) # bins 구간의 갯수
plt.show()

np.random.rand¶
- 난수: [0. 1)의 균등 분포(Uniform Distribution) 형상으로 표본 추출
In [108]:
data = np.random.rand(10000)
print(data)
import matplotlib.pyplot as plt
plt.hist(data, bins=10)
plt.show()

np.random.randn¶
- 난수: 표준 정규 분포(standard normal distribution)에서 표본 추출
In [109]:
a = np.random.randn(2, 4)
pprint(a)
In [111]:
data = np.random.randn(10000)
import matplotlib.pyplot as plt
plt.hist(data, bins=30)
plt.show()

np.random.randint¶
- numpy.random.randint(low, high=None, size=None, dtype='l')
- 지정된 shape으로 배열을 만들고 low 부터 high 미만의 범위에서 정수 표본 추출
In [112]:
a = np.random.randint(5, 10, size=(2, 4))
pprint(a)
In [113]:
a = np.random.randint(1, size=10)
pprint(a)
In [114]:
data = np.random.randint(-100, 100, 10000)
import matplotlib.pyplot as plt
plt.hist(data, bins=10)
plt.show()

rand vs random¶
- random.random 은 random.random_sample 의 alias
- 인자로 dimension 주는 방법이 다름
In [123]:
np.random.rand(3,5)
Out[123]:
In [124]:
np.random.random((3,5))
Out[124]:
2.5 약속된 난수¶
- np.random.seed 값을 설정 하여 난수 발생 재연
In [133]:
# seed 없이 random 사용
np.random.rand(2,3)
Out[133]:
In [134]:
np.random.rand(2,3)
Out[134]:
In [4]:
# seed 설정 후 random 사용
np.random.seed(0)
In [128]:
np.random.rand(2,3)
Out[128]:
In [7]:
np.random.randint(0, 10, (2,3))
Out[7]:
In [8]:
np.random.seed(0)
In [9]:
np.random.rand(2,3)
Out[9]:
In [10]:
np.random.randint(0, 10, (2,3))
Out[10]:
데이터 타입¶
- 배열을 생성할 때 dtype속성으로 지정
- np.int64 : 64 비트 정수 타입
- np.float32 : 32 비트 부동 소수 타입
- np.complex : 복소수 (128 float)
- np.bool : 불린 타입 (Trur, False)
- np.object : 파이썬 객체 타입
- np.string_ : 스트링 타입
- np.unicode_ : 유니코드 타입
배열 상태 검사(Inspecting)¶
- 배열 shape np.ndarray.shape 속성 arr.shape (5, 2, 3)
- 배열 길이 일차원의 배열 길이 확인 len(arr) 5
- 배열 차원 np.ndarray.ndim 속성 arr.ndim 3
- 배열 요소 수 np.ndarray.size 속성 arr.size 30
- 배열 타입 np.ndarray.dtype 속성 arr.dtype dtype(‘float64’)
- 배열 타입 명 np.ndarray.dtype.name 속성 arr.dtype.name float64
- 배열 타입 변환 np.ndarray.astype 함수 arr.astype(np.int) 배열 타입 변환
In [11]:
#데모 배열 객체 생성
arr = np.random.random((5,2,3))
In [12]:
#배열 타입 조회
type(arr)
Out[12]:
In [13]:
# 배열의 shape 확인
arr.shape
Out[13]:
In [14]:
# 배열의 길이
len(arr)
Out[14]:
In [15]:
# 배열의 차원 수
arr.ndim
Out[15]:
In [16]:
# 배열의 요소 수: shape(k, m, n) ==> k*m*n
arr.size
Out[16]:
In [17]:
# 배열 타입 확인
arr.dtype
Out[17]:
In [18]:
# 배열 요소를 int로 변환
# 요소의 실제 값이 변환되는 것이 아님
# View의 출력 타입과 연산을 변환하는 것
arr.astype(np.int)
Out[18]:
In [19]:
# np.float으로 타입을 다시 변환하면 np.int 변환 이전 값으로 모든 원소 값이 복원됨
arr.astype(np.float)
Out[19]:
도움말¶
- NumPy의 모든 API는 np.info 함수를 이용하여 도움말을 확인
In [20]:
np.info(np.ndarray.dtype)
배열 연산¶
배열 일반 연산¶
산술 연산(Arithmetic Operations)¶
- 기본 연산자 연산자 재정의
In [23]:
# arange로 1부터 10 미만의 범위에서 1씩 증가하는 배열 생성
# 배열의 shape을 (3, 3)으로 지정
a = np.arange(1, 10).reshape(3, 3)
pprint(a)
In [24]:
# arange로 9부터 0까지 범위에서 1씩 감소하는 배열 생성
# 배열의 shape을 (3, 3)으로 지정
b = np.arange(9, 0, -1).reshape(3, 3)
pprint(b)
In [25]:
# 배열 연산: 뺄셈, -
a - b
Out[25]:
In [26]:
np.subtract(a, b)
Out[26]:
In [27]:
# 배열 연산: 덧셈, +
a + b
Out[27]:
In [28]:
np.add(a, b)
Out[28]:
In [29]:
# 배열 연산: 곱셈, *
a * b
Out[29]:
In [30]:
np.multiply(a, b)
Out[30]:
In [31]:
# 배열 연산: 나눗셈, /
a / b
Out[31]:
In [32]:
np.divide(a, b)
Out[32]:
In [33]:
# 배열 연산: 지수
np.exp(a)
Out[33]:
In [34]:
# 배열 연산: 제곱근
np.sqrt(a)
Out[34]:
In [35]:
# 배열 연산: sin
np.sin(a)
Out[35]:
In [36]:
# 배열 연산: cos
np.cos(a)
Out[36]:
In [37]:
# 배열 연산: tan
np.tan(a)
Out[37]:
In [38]:
# 배열 연산: log
np.log(a)
Out[38]:
In [40]:
# 배열 연산: dot product, 내적
np.dot(a, b)
Out[40]:
비교 연산(Comparison)¶
배열의 요소별 비교 (Element-wise)¶
- 기본 연산자를 이용하여 요소별 비교
In [41]:
a == b
Out[41]:
In [42]:
a > b
Out[42]:
배열 비교 (Array-wise)¶
- 두 배열 전체는 np.array_equal 함수를 사용하여 비교
In [43]:
np.array_equal(a, b)
Out[43]:
집계 함수(Aggregate Functions)¶
- NumPy의 모든 집계 함수는 집계 함수는 AXIS를 기준으로 계산
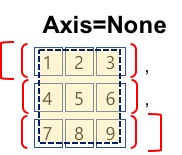
집계함수에 AXIS를 지정하지 않으면 axis=None
axis=None
- aixs=None은 전체 행렬을 하나의 배열로 간주하고 집계 함수의 범위를 전체 행렬로 정의합니다.
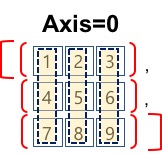
- axis=0
- aixs=0은 행을 기준으로 각 행의 동일 인덱스의 요소를 그룹으로 합니다.
- 각 그룹을 집계 함수의 범위로 정의합니다.
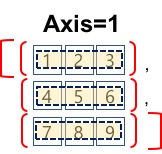
- axis=1
- aixs=1은 열을 기준으로 각 열의 요소를 그룹으로 합니다.
- 각 그룹을 집계 함수의 범위로 정의합니다.
- axis 관련해서는 3차원 ==> Numpy에서 np.sum 함수의 axis 이해를 참조
In [49]:
# arange로 1부터 10미만의 범위에서 1씩 증가하는 배열 생성
# 배열의 shape을 (3, 3)으로 지정
a = np.arange(1, 10).reshape(3, 3)
pprint(a)
[ndarray 배열 객체].sum(), np.sum(): 합계¶
- 지정된 axis를 기준으로 요소의 합을 반환
In [44]:
a.sum(), np.sum(a)
Out[44]:
In [50]:
a.sum(axis=0), np.sum(a, axis=0)
Out[50]:
In [51]:
a.sum(axis=1), np.sum(a, axis=1)
Out[51]:
[ndarray 배열 객체].min(), np.min(): 최소값¶
- 지정된 axis를 기준으로 요소의 최소값을 반환
In [54]:
a.min(), np.min(a)
Out[54]:
In [55]:
a.min(axis=0), np.min(a, axis=0)
Out[55]:
In [56]:
a.min(axis=1), np.min(a, axis=1)
Out[56]:
[ndarray 배열 객체].max(), np.max(): 최대값¶
- 지정된 axis를 기준으로 요소의 최대값을 반환
In [57]:
a.max(), np.max(a)
Out[57]:
In [58]:
a.max(axis=0), np.max(a, axis=0)
Out[58]:
In [59]:
a.max(axis=1), np.max(a, axis=1)
Out[59]:
[ndarray 배열 객체].cumssum(), np.cumsum(): 누적 합계¶
- 지정된 axis를 기준으로 각 요소의 누적 합의 결과를 반환
In [60]:
a.cumsum(), np.cumsum(a)
Out[60]:
In [61]:
a.cumsum(axis=0), np.cumsum(a, axis=0)
Out[61]:
In [62]:
a.cumsum(axis=1), np.cumsum(a, axis=1)
Out[62]:
[ndarray 배열 객체].mean(), np.mean(): 평균¶
- 지정된 axis를 기준으로 요소의 평균을 반환
In [63]:
a.mean(), np.mean(a)
Out[63]:
In [64]:
a.mean(axis=0), np.mean(a, axis=0)
Out[64]:
In [65]:
a.mean(axis=1), np.mean(a, axis=1)
Out[65]:
np.mean(): 중앙값¶
- 지정된 axis를 기준으로 요소의 중앙값을 반환
In [73]:
np.median(a)
Out[73]:
In [70]:
np.median(a, axis=0)
Out[70]:
In [71]:
np.median(a, axis=1)
Out[71]:
np.corrcoef(): (상관계수)Correlation coeficient¶
In [69]:
np.corrcoef(a)
Out[69]:
[ndarray 배열 객체].std(), np.std(): 표준편차¶
- 지정된 axis를 기준으로 요소의 표준 편차를 계산
In [74]:
a.std(), np.std(a)
Out[74]:
In [75]:
a.std(axis=0), np.std(a, axis=0)
Out[75]:
In [76]:
a.std(axis=1), np.std(a, axis=1)
Out[76]:
브로드캐스팅¶
Shape이 같은 두 배열에 대한 이항 연산은 배열의 요소별로 수행됩니다. 두 배열 간의 Shape이 다를 경우 두 배열 간의 형상을 맞추는 <그림 2>의 Broadcasting 과정을 거칩니다.
그림 2: 브로드캐스트 작동 원리
In [77]:
# 데모 배열 생성
a = np.arange(1, 25).reshape(4, 6)
pprint(a)
b = np.arange(25, 49).reshape(4, 6)
pprint(b)
In [78]:
a+b
Out[78]:
Shape이 다른 두 배열의 연산¶
- Shape이 다른 두 배열 사이의 이항 연산에서 브로드케스팅 발생
- 두 배열을 같은 Shape으로 만든 후 연산을 수행
In [79]:
a+100
Out[79]:
a + 100은 다음과 같은 과정을 거쳐 처리 됩니다.¶
In [80]:
# step 1: 스칼라 배열 변경
new_arr = np.full_like(a, 100)
pprint(new_arr)
In [81]:
# step 2: 배열 이항 연산
a+new_arr
Out[81]:
Case 2: Shaep이 다른 배열들의 연산¶
In [82]:
# 데모 배열 생성
a = np.arange(5).reshape((1, 5))
pprint(a)
b = np.arange(5).reshape((5, 1))
pprint(b)
In [83]:
a + b
Out[83]:
백터연산¶
- 반복문 처리 속도 비교
In [6]:
import numpy as np
# sample array
a = np.arange(10000000)
In [7]:
result = 0
In [13]:
%%time
for v in a:
result += v
In [88]:
result
Out[88]:
In [89]:
%%time
result = np.sum(a)
In [90]:
result
Out[90]:
배열 복사¶
[ndarray 배열 객체].copy(), np.copy()¶
In [16]:
#데모용 배열
a = np.random.randint(0, 9, (3, 3))
pprint(a)
In [17]:
copied_a1 =np.copy(a)
배열 정렬¶
- ndarray 객체는 axis를 기준으로 요소 정렬하는 sort 함수
In [19]:
#배열 생성
unsorted_arr = np.random.random((3, 3))
pprint(unsorted_arr)
In [20]:
#데모를 위한 배열 복사
unsorted_arr1 = unsorted_arr.copy()
unsorted_arr2 = unsorted_arr.copy()
unsorted_arr3 = unsorted_arr.copy()
In [23]:
#배열 정렬
unsorted_arr1.sort()
pprint(unsorted_arr1)
In [24]:
#배열 정렬, axis=0
unsorted_arr2.sort(axis=0)
pprint(unsorted_arr2)
In [25]:
#배열 정렬, axis=1
unsorted_arr3.sort(axis=1)
pprint(unsorted_arr3)
서브셋, 슬라이싱, 인덱싱¶
요소 선택¶
- 배열의 각 요소는 axis 인덱스 배열로 참조
- 1차원 배열은 1개 인덱스, 2차원 배열은 2개 인덱스, 3차원 인덱스는 3개 인덱스로 요소를 참조
- 인덱스로 참조한 요소는 값 참조, 값 수정이 모두 가능
In [27]:
# 데모 배열 생성
a0 = np.arange(24) # 1차원 배열
pprint(a0)
a1 = np.arange(24).reshape((4, 6)) #2차원 배열
pprint(a1)
a2 = np.arange(24).reshape((2, 4, 3)) # 3차원 배열
pprint(a2)
1 차원 배열 요소 참조 및 변경¶
In [28]:
a0[5] # 5번 인덱스 요소 참조
Out[28]:
In [29]:
# 5번 인덱스 요소 업데이트
a0[5] = 1000000
In [30]:
pprint(a0)
2 차원 배열 요소 참조 및 변경¶
In [31]:
pprint(a1)
In [32]:
# 1행 두번째 컬럼 요소 참조
a1[0, 1]
Out[32]:
In [33]:
# 1행 두번째 컬럼 요소 업데이트
a1[0, 1]=10000
In [34]:
pprint(a1)
3 차원 배열 요소 참조 및 변경¶
In [35]:
pprint(a2)
In [36]:
# 2 번째 행, 첫번째 컬럼, 두번째 요소 참조
a2[1, 0, 1]
Out[36]:
In [37]:
a2[1, 0, 1]=10000
In [38]:
pprint(a2)
슬라이싱(Slicing)¶
- 여러개의 배열 요소를 참조할 때 슬라이싱을 사용
- 슬라이싱은 axis 별로 범위를 지정하여 실행
- [from_index:to_index]
- from_index는 범위의 시작 인덱스이며, to_index는 범위의 종료 인덱스
- to_index는 결과에 포함되지 않음
- from_index는 생략 가능, 생략할 경우 0을 지정한 것으로 간주
- to_index 역시 생략 가능, 이 경우 마지막 인덱스로 설정됩니다.
- [ : ] 는 전체 범위
- from_index와 to_index에 음수를 지정하면 이것은 반대 방향
- -1은 마지막 인덱스를 의미
- 슬라이싱은 원본 배열의 뷰
- 슬라이싱 결과의 요소를 업데이트하면 원본에 반영
In [39]:
# 데모 배열 생성
a1 = np.arange(1, 25).reshape((4, 6)) #2차원 배열
pprint(a1)
가운데 요소 가져오기

In [40]:
a1[1:3, 1:5]
Out[40]:
음수 인덱스를 이용한 범위 설정¶

In [41]:
a1[1:-1, 1:-1]
Out[41]:
In [42]:
# 슬라이싱 배열
slide_arr = a1[1:3, 1:5]
pprint(slide_arr)
In [46]:
# 슬라이싱 결과 배열에 슬라이싱을 적용하여 4개 요소 참조
slide_arr2 = slide_arr[:, 1:3]
pprint(slide_arr2)
In [47]:
# 슬라이싱을 적용하여 참조한 4개 요소 업데이트 및 슬라이싱 배열 조회
slide_arr[:, 1:3]=99999
pprint(slide_arr)
In [48]:
pprint(a1)
블린 인덱싱(Boolean Indexing)¶
- 배열 각 요소의 선택 여부를 True, False 지정하는 방식
- 해당 인덱스의 True만을 조회
In [49]:
# 데모 배열 생성
a1 = np.arange(1, 25).reshape((4, 6)) #2차원 배열
pprint(a1)
In [50]:
# 짝수인 요소 확인
# numpy broadcasting을 이용하여 짝수인 배열 요소 확인
even_arr = a1%2==0
pprint(even_arr)
In [51]:
# a1[a1%2==0] 동일한 의미입니다.
a1[even_arr]
Out[51]:
In [52]:
np.sum(a1)
Out[52]:
Boolean Indexing의 응용¶
- 구글 : seattle2014.csv 검색
- 2014년 시애클 강수량 데이터:
- 2014년 시애틀 1월 평균 강수량은?
In [54]:
# 데이터 로딩
import pandas as pd
rains_in_seattle = pd.read_csv("Seattle2014.csv")
rains_arr = rains_in_seattle['PRCP'].values
print("Data Size:", len(rains_arr))
In [55]:
# 날짜 배열
days_arr = np.arange(0, 365)
In [56]:
days_arr
Out[56]:
In [59]:
# 1월의 날수 boolean index 생성
condition_jan = days_arr < 31
condition_jan
Out[59]:
In [60]:
# 40일 조회
condition_jan[:40]
Out[60]:
In [63]:
#1월의 강수량 추출
rains_jan = rains_arr[condition_jan]
rains_jan
Out[63]:
In [62]:
#강수량 데이터 수 (1월: 31일)
len(rains_jan)
Out[62]:
In [64]:
# 1월 강수량 총합
np.sum(rains_jan)
Out[64]:
In [65]:
# 1월 평균 강수향
np.mean(rains_jan)
Out[65]:
팬시 인덱싱(Fancy Indexing)¶
- 배열에 인덱스 배열을 전달하여 요소를 참조
In [66]:
arr = np.arange(1, 25).reshape((4, 6))
pprint(arr)
In [67]:
[arr[0,0], arr[1, 1], arr[2, 2], arr[3, 3]]
Out[67]:
In [68]:
# 두 배열을 전달==> (0, 0), (1,1), (2,2), (3, 3)
arr[[0, 1, 2, 3], [0, 1, 2, 3]]
Out[68]:
In [69]:
# 전체 행에 대해서, 1, 2번 컬럼 참조
arr[:, [1, 2]]
Out[69]:
배열 변환¶
전치(Transpose)¶
- Tranpose는 행렬의 인덱스가 바뀌는 변환
- [numpy.ndarray 객체].T 속성을 사용
$$
\begin{bmatrix}1 & 2 \end{bmatrix}^T
=
\begin{bmatrix} 1 \\ 2 \end{bmatrix}
$$
$$
\begin{bmatrix}1 & 2 \\ 3 & 4 \end{bmatrix} ^T
=
\begin{bmatrix}1 & 3 \\ 2 & 4 \end{bmatrix}
$$
$$
\begin{bmatrix}1 & 2 \\ 3 & 4 \\ 5 & 6 \end{bmatrix} ^T
=
\begin{bmatrix}1 & 3 & 5 \\ 2 & 4 & 6 \end{bmatrix}
$$
In [70]:
# 행렬 생성
a = np.random.randint(1, 10, (2, 3))
pprint(a)
In [71]:
#행렬의 전치
pprint(a.T)
배열 형태 변경¶
- ravel은 배열의 shape을 1차원 배열로 만드는 메서드
- reshape은 데이터 변경없이 지정된 shape으로 변환하는 메서드
[numpy.ndarray 객체].ravel()¶
- 배열을 1차원 배열로 반환하는 메서드
- numpy.ndarray 배열 객체의 View를 반환
- 배열의 요소를 수정하면 원본 배열 요소에도 반영
In [72]:
# 데모 배열 생성
a = np.random.randint(1, 10, (2, 3))
pprint(a)
In [74]:
a.ravel()
Out[74]:
In [75]:
b = a.ravel()
pprint(b)
In [77]:
b[0]=99
pprint(b)
pprint(a)
[numpy.ndarray 객체].reshape()¶
- [numpy.ndarray 객체]의 shape 정보 변경
In [78]:
# 대상 행렬 속성 확인
a = np.random.randint(1, 10, (2, 3))
pprint(a)
In [79]:
result = a.reshape((3, 2, 1))
pprint(result)
배열 요소 추가 삭제¶
- 배열의 요소를 변경, 추가, 삽입 및 삭제하는 resize, append, insert, delete 함수
np.resize(a, new_shape)¶
- np.resize와 np.reshape 함수는 배열의 shape을 변경한다는 부분에서 유사
- resize는 shape을 변경하는 과정에서 배열 요소 수를 줄이거나 늘릴 수 있음
일반적인 resize 사용 방법¶
In [80]:
#배열 생성
a = np.random.randint(1, 10, (2, 6))
pprint(a)
In [81]:
# shape 변경 - 요소 수 변경 없음
a.resize((6, 2))
pprint(a)
요소 수가 늘어난 변경¶
In [82]:
#배열 생성
a = np.random.randint(1, 10, (2, 6))
pprint(a)
In [83]:
# 요소수 12개에서 20개로 늘어남
# 늘어난 요소는 0으로 채워짐
a.resize((2, 10))
pprint(a)
요소 수가 즐어든 변경¶
In [84]:
#배열 생성
a = np.random.randint(1, 10, (2, 6))
pprint(a)
In [86]:
# 요소수 12개에서 9개로 줄임
a.resize((3, 3))
pprint(a)
np.append(arr, values, axis=None)¶
- 배열의 끝에 값을 추가
- axis로 배열이 추가되는 방향을 지정
In [87]:
# 데모 배열 생성
a = np.arange(1, 10).reshape(3, 3)
pprint(a)
b = np.arange(10, 19).reshape(3, 3)
pprint(b)
case 1: axis을 지정하지 않을 경우¶
- axis를 지정하지 않으면 배열은 1차원 배열로 변형되어 결합
In [88]:
# axis 지정 없이 추가
result = np.append(a, b)
pprint(result)
In [89]:
#원본 배열을 변경하는 것이 아니며 새로운 배열이 생성됩니다.
pprint(a)
case 2: axis=0 지정¶
In [90]:
# axis = 0, 행방향
# axis 0 방향으로 b 배열 추가
result = np.append(a, b, axis=0)
pprint(result)
case 3: axis=1 지정¶
In [92]:
# axis = 1 열방향
# axis 1 방향으로 b 배열 추가
result = np.append(a, b, axis=1)
pprint(result)
np.insert(arr, obj, values, axis=None)¶
- axis를 지정하지 않으며 1차원 배열로 변환
- 추가할 방향을 axis로 지정
In [93]:
# 데모 배열 생성
a = np.arange(1, 10).reshape(3, 3)
pprint(a)
In [94]:
# a 배열을 일차원 배열로 변환하고 1번 index에 99 추가
np.insert(a, 1, 999)
Out[94]:
In [95]:
# a 배열의 axis 0 방향 1번 인덱스에 추가
# index가 1인 row에 999가 추가됨
np.insert(a, 1, 999, axis=0)
Out[95]:
In [96]:
# a 배열의 axis 1 방향 1번 인덱스에 추가
# index가 1인 column에 999가 추가됨
np.insert(a, 1, 999, axis=1)
Out[96]:
np.delete(arr, obj, axis=None)¶
- axis를 지정하지 않으며 1차원 배열로 변환
- 삭제할 방향을 axis로 지정
- delete 함수는 원본 배열을 변경하지 않으며 새로운 배열을 반환
In [97]:
# 데모 배열 생성
a = np.arange(1, 10).reshape(3, 3)
pprint(a)
In [98]:
# a 배열을 일차원 배열로 변환하고 1번 index 삭제
np.delete(a, 1)
Out[98]:
In [100]:
# a 배열의 axis 0 방향 1번 인덱스인 행을 삭제한 배열을 생성하여 반환
np.delete(a, 1, axis=0)
Out[100]:
In [101]:
# a 배열의 axis 1 방향 1번 인덱스인 열을 삭제한 배열을 생성하여 반환
np.delete(a, 1, axis=1)
Out[101]:
In [102]:
a
Out[102]:
배열 결합¶
- 배열과 배열을 결합하는 np.concatenate, np.vstack, np.hstack 함수를 제공
배열 결합 concatenate((a1, a2, ...), axis=0)¶
In [103]:
# 데모 배열
a = np.arange(1, 7).reshape((2, 3))
pprint(a)
b = np.arange(7, 13).reshape((2, 3))
pprint(b)
In [104]:
# axis=0 방향으로 두 배열 결합, axis 기본값=0
result = np.concatenate((a, b))
result
Out[104]:
In [107]:
# axis=0 방향으로 두 배열 결합, 결과 동일
result = np.concatenate((a, b), axis=0)
result
Out[107]:
In [108]:
# np.append(a, b, axis=0) 와 동일
np.append(a, b, axis=0)
Out[108]:
In [109]:
# axis=1 방향으로 두 배열 결합, 결과 동일
result = np.concatenate((a, b), axis=1)
result
Out[109]:
In [110]:
# np.append(a, b, axis=0) 와 동일
np.append(a, b, axis=1)
Out[110]:
수직 방향 배열 결합¶
np.vstack
- np.vstack(tup)
- tup: 튜플
- 튜플로 설정된 여러 배열을 수직 방향으로 연결 (axis=0 방향)
- np.concatenate(tup, axis=0)와 동일
In [111]:
# 데모 배열
a = np.arange(1, 7).reshape((2, 3))
pprint(a)
b = np.arange(7, 13).reshape((2, 3))
pprint(b)
In [112]:
np.vstack((a, b))
Out[112]:
In [113]:
# 4개 배열을 튜플로 설정
np.vstack((a, b, a, b))
Out[113]:
수평 방향 배열 결합¶
np.hstack
- np.hstack(tup)
- tup: 튜플
- 튜플로 설정된 여러 배열을 수평 방향으로 연결 (axis=1 방향)
- np.concatenate(tup, axis=1)와 동일
In [114]:
np.hstack((a, b))
Out[114]:
In [115]:
np.hstack((a, b, a, b))
Out[115]:
배열 분리¶
NumPy는 배열을 수직, 수평으로 분할하는 함수를 제공합니다.
- np.hsplit(): 지정한 배열을 수평(행) 방향으로 분할
- np.vsplit(): 지정한 배열을 수직(열) 방향으로 분할
In [116]:
# 분할 대상 배열 생성
a = np.arange(1, 25).reshape((4, 6))
pprint(a)
In [119]:
# 수평으로 두 그룹으로 분할하는 함수
result = np.hsplit(a, 2)
result
Out[119]:
In [120]:
result[0]
Out[120]:
In [121]:
# 수평으로 두 그룹으로 분할하는 함수
result = np.hsplit(a, 3)
result
Out[121]:
In [122]:
result[0]
Out[122]:
In [133]:
# a.shape[1] -> 6
# a[:, :1], a[:, 1:3], a[:, 3:5], a[:, 5:]
rs = np.hsplit(a, [1,3,5])
In [134]:
rs[0]
Out[134]:
In [135]:
rs[1]
Out[135]:
In [136]:
rs[2]
Out[136]:
In [137]:
rs[3]
Out[137]:
배열 수직 분할¶
- np.vsplit(ary, indices_or_sections)
- 배열을 수직 방향(행 방향)으로 분할하는 함수
In [139]:
# 분할 대상 배열 생성
a = np.arange(1, 25).reshape((4, 6))
pprint(a)
In [140]:
result=np.vsplit(a, 2)
result
Out[140]:
In [141]:
np.array(result).shape
Out[141]:
In [142]:
result=np.vsplit(a, 4)
result
Out[142]:
In [143]:
np.array(result).shape
Out[143]:
In [144]:
# row를 1, 2-3, 4번째 라인으로 구분
np.vsplit(a, [1, 3])
Out[144]:
In [ ]: